Unsere Vermögensberaterinnen und Vermögensberatern arbeiten als Selbstständige zu unterschiedlichsten Uhrzeiten, an unterschiedlichen Orten und mit unterschiedlichen Endgeräten. Vertriebszeit ist wertvoll, und die zunehmend digitale Unterstützung des Kontakts zwischen Endkunden und Vermögensberatern muss sich ideal in die Gesprächssituation einfügen.
Um unsere Vermögensberater in ihrer Arbeit bestmöglich zu unterstützen, ist es unser Anspruch in der Anwendungsentwicklung, ihnen eine maximal stabile und zuverlässige Anwendungslandschaft bereitzustellen. Für uns bedeutet das, den Fokus auf hohe Qualität und effektive Betreibbarkeit zu setzen. Hierzu zählt auch, einfach und zielführend nachvollziehen zu können, wie sich unsere Anwender durch die Systeme bewegen.
Ausgangslage und Optimierungspotenzial
Bei der DVAG vollziehen wir derzeit die letzten Schritte unserer Cloud-Transformation. Diese Transformation haben wir nicht als Lift & Shift, sondern in weiten Teilen als Ablösung und Neuentwicklung mittels Cloud-Native-Technologien vollzogen. Hierdurch entsteht eine Anwendungslandschaft, die zunehmend verteilt wird. Schon - aus Nutzersicht - einfache Operationen lösen im Hintergrund oftmals eine Vielzahl an Service-Aufrufen aus.
Im Falle einer produktiven Störung ist in solch einer verteilten Architektur die Beantwortung der folgenden beispielhaften Fragen alles andere als leicht:
- Eine User*in meldet, dass eine Anwendung langsam ist. Welcher technische Service ist dafür verantwortlich?
- Eine User*in meldet, dass ein Fehler aufgetreten ist. Welcher technische Service hat den Fehler verursacht?
- Ein automatisierter Alarm weist auf einen Fehler in einer Komponente hin. Welche Anfragen / Business-Prozesse sind davon betroffen?
- Wie viel Prozent der Anfragen sind aktuell fehlerhaft? Haben wir einen Major Incident?
Zielsetzung
Wir möchten uns in die Lage versetzen, Fragestellungen wie die zuvor genannten trotz unserer Microservice-Architektur bestmöglich beantworten können und damit im Betrieb dieser dezentralen Anwendungslandschaft den Überblick behalten.
Zu diesem Zweck wollen wir zur Laufzeit automatisiert die folgenden anonymisierte Telemetriedaten erheben:
- Logs: Logs bzw. Protokolle zeichnen Ereignisse, Fehler und Warnungen samt Zeitstempel auf, die während der Ausführung einer Anwendung entstanden sind. Hierin sind in der Regel weiterführende Informationen wie Stack Traces enthalten, die im Fehlerfall Aufschlüss über die konkret betroffene Code-Stelle geben.
- Traces: Traces sind die “Wegpunkte”, die eine technischer Request vom System des Nutzers über die involvierten Anwendungen, Systeme und Datenbanken sowie zurück zum Nutzer nimmt. Sie geben bspw. Aufschluss über Performance-Engpässe und Fehler-Kernursachen in einem verteilten System.
- Metriken: Metriken in unserem Kontext sind quantifizierbare Echtzeit-Messwerte. Diese geben bspw. Aufschluss über Laufzeiten, Fehlerraten und Speicherverbrauch einer Applikation.
Herausforderung
Eine Herausforderung unserer Microservice-Architektur ist die Anzahl der Software-Artefakte. Es ist wichtig, dass die Herstellung und Wartung der Services effizient ist. Daher ist es für uns wünschenswert, dass eine Lösung zur Erhebung von Telemetriedaten weitestgehend out of the box funktioniert. Dies ist jedoch in der Realität gar nicht so einfach.
Zum einen herrscht in unserer Cloud-Landschaft ein gewisser Grad an Technologie-Hetegerogenität. Es kommen (trotz weitgehender Standardisierung) verschiedene Programmiersprachen, Frameworks und Bibliotheken zum Einsatz.
Zum anderen werden Softwarekomponenten teilweise nicht von uns selbst, sondern von Partner-Unternehmen betrieben und nahtlos in unsere Anwendungen und Portale integriert. Diese Partner arbeiten teilweise mit anderen Programmiersprachen und Frameworks, aber auch mit anderen Cloud-Providern. Hieraus ergeben sich Anforderungen an die Analysierbarkeit des Systemverhaltens über System-, Provider- und Technologie-Grenzen hinweg.
Wir benötigen daher eine Lösung, die uns unabhängig von der Technologie eine einheitliche Sicht auf die Anwendung(en) ermöglicht.
Auf der Suche nach einer praktikablen Lösung für diese Herausforderungen sind wir auf OpenTelemetry gestoßen.
OpenTelemetry als Standard für Telemetriedaten
OpenTelemetry hat sich in den vergangenen Jahren als de-facto Standard für die Erfassung und Verarbeitung von Telemetriedaten in verteilten Systemen etabliert. Es handelt sich um ein Projekt der Cloud Native Computing Foundation (CNCF) und ist als Merger aus den beiden vorangegangenen Initativen OpenTracing und OpenCensus hervorgegangen.
Der offene Telemetrie-Standard unterstützt die standardisierte Erzeugung und Verarbeitung von Logs, Traces und Metriken, um die Funktionsweise komplexer Microservice-Architekturen besser zu verstehen und zu überwachen. Hierbei wird er wiederum von relevanten Analyse-Werkzeugen wie Azure Application Insights, Dynatrace und Splunk unterstützt.
Im Folgenden werden wir die wichtigsten Konzepte von OpenTelemetry vorstellen. Hier spielen insbesondere die Begriffe Traces, Spans und Trace Context Propagation eine wichtige Rolle, da sie die Grundlage für die Analyse von verteilten Systemen bilden.
Traces, Spans und Trace Context Propagation
Ein Trace ist eine verteilte Operation mit eindeutiger Trace ID, die sich über mehrere Services oder Komponenten erstrecken kann.
Schon wenn ein User in einem unserer Web-Frontends auf einen Button klickt, entsteht ein Trace. Unter einem Trace
werden alle Interaktionen (sogenannte Spans) zwischen verschiedenen Services in zeitlicher Abfolge gespeichert.
Spans bilden die kleinste Einheit innerhalb eines Traces. Ein Span repräsentiert eine einzelne Operation oder einen Prozess innerhalb des Gesamtablaufs. Jeder Span enthält:
- Eine eindeutige
Span ID. - Einen Namen, der die Operation beschreibt (z. B. „Datenbankabfrage“, “API-X-Aufruf”).
- Einen Zeitstempel, der den Start und die Dauer angibt.
- Attribute: Metadaten, die zusätzliche Informationen über den Span enthalten.
- Status: Den Erfolg oder das Scheitern der Operation.
- Beziehungen: Verknüpfungen zu anderen Spans, wie ein übergeordneter Span (Parent) oder abhängige Spans (Children).
Trace Context Propagation bezeichnet den Mechanismus, wie der Trace Context bestehend aus Trace ID und Span ID über Prozess-, Service- und Netzwerkgrenzen hinweg weitergegeben wird.
Die Propagation stellt sicher, dass alle beteiligten Dienste den Trace- und Span-Zusammenhang korrekt verknüpfen können. OpenTelemetry verwendet dafür das W3C Trace Context Format.
Der traceparent HTTP-header aus dem W3C Trace Context Format enthält die Trace ID und Span ID und wird zur Übertragung des Trace Contexts zwischen Services verwendet.
Beispiel
Die folgende Tabelle zeigt an einem Beispiel, wie ein Trace mit mehreren Spans aussehen könnte.
| Timestamp | Span Name | Status | Dauer (ms) | Span ID | Parent Span ID | traceparent |
|---|---|---|---|---|---|---|
| 2025-01-23 10:00:00.000 | service-abc.my-org.com POST /api/v3/resource | Success | 270 | root | - | 00-4bf92f3577b34da6a3ce929d0e0e4736-root-01 |
| 2025-01-23 10:00:00.050 | –another-service.third-party.com GET /api/v2/sth | Success | 200 | S1 | root | 00-4bf92f3577b34da6a3ce929d0e0e4736-S1-01 |
| 2025-01-23 10:00:00.070 | —-mongo.third-party.com MONGO db.users.findOne({_id: ...}) | Success | 150 | S2 | S1 | 00-4bf92f3577b34da6a3ce929d0e0e4736-S2-01 |
| 2025-01-23 10:00:00.210 | –my-database.my-org.com SQL SELECT 1 from dual | Success | 50 | S3 | root | 00-4bf92f3577b34da6a3ce929d0e0e4736-S3-01 |
Hier sieht man folgendes Aufrufverhalten:
- Es wurde (bspw. durch eine im Browser laufende Webanwendung) ein HTTP POST Request an den Service
service-abc.my-org.comausgelöst, der im Trace die Span IDrooterhält. Dieser Service ruft zwei folgende Services auf:another-service.third-party.comper HTTP GET Request, dieser erhält die Span IDS1. Auch dieser Service ruft einen weiteren Service auf:- eine NoSQL-Abfrage auf dem Datenbank-Server
mongo.third-party.com, der die Span IDS2erhält.
- eine NoSQL-Abfrage auf dem Datenbank-Server
- Eine SQL-Abfrage auf dem Datenbank-Server
my-database.my-org.com, diese erhält die Span IDS2.
OpenTelemetry-Integration
Die Grundidee hinter OpenTelemetry ist einfach: Jedem Request werden die oben genannten Trace-Informationen hinzugefügt, die am Ende einen zusammenhängen Trace ergeben. Die ggfls. naheliegende Idee, dies händisch zu implementieren, ist jedoch nicht angezeigt: Mit Blick auf die schiere Menge der in unserer Architektur enthaltenen Services und Systeme wie bspw. Datenbanken stößt dieser Ansatz schnell an Grenzen: Neben einem hohen Implementierungs-Aufwand sei auch die Fehleranfälligkeit genannt, die bei der Implementierung durch vielzählige Entwicklungsteams entstehen kann.
Für viele Standard-Technologien gibt es stattdessen fertige Bibliotheken, die OpenTelemetry per Code-Instrumentierung hinzufügen - d.h. ganz ohne Anpassung der Client-seitigen Aufrufe oder der entsprechenden Server-seitigen Request Handler.
Für Java- und Kotlin-Backends gibt es z.B. den Open Telemtry Java Agent. Der Agent nutzt aspektorientierte Programmierung, um automatisch Trace-Informationen zu generieren und zu propagieren. Hierbei werden eine Vielzahl von Frameworks und Bibliotheken unterstützt, wie z.B. Spring, diverse HTTP-Clients, diverse Message Queues sowie JDBC.
Der Einsatz dieser fertigen und gepflegten Bibliotheken ist der Weg, den wir in der DVAG verfolgen.
Umfassende Unterstützung
OpenTelemetry ist ein Standard, der von vielen Cloud-Providern und Monitoring-Tools unterstützt wird.
Unsere Recherche hat das folgende Ergebnis zur Unterstützung durch die gängigsten Hyperscaler und Observability-Lösungen ergeben (Stand Mai 2025):
| Werkzeug | Traces | Metriken | Logs | Native OTel-Unterstützung | Anmerkungen |
|---|---|---|---|---|---|
| AWS X-Ray | ✅ | ✅ | ✅ (via CloudWatch) | ✅ | AWS Distro for OpenTelemetry (ADOT). |
| Azure Monitor | ✅ | ✅ | ✅ | ✅ | Unterstützt vollständige OpenTelemetry-Integration. |
| Elastic | ✅ | ✅ | ✅ | ✅ | Vereinheitlichte Observability mit Elastic APM und OpenTelemetry. |
| Google Cloud Trace | ✅ | ✅ | ✅ | ✅ | Integriert in die Google Cloud Operations Suite. |
| Jaeger | ✅ | ❌ | ❌ | ✅ | Fokus auf Tracing; für Metriken/Logs andere Tools verwenden. |
| New Relic | ✅ | ✅ | ✅ | ✅ | Unterstützt OTel für vollständige Observability. |
| Dynatrace | ✅ | ✅ | ✅ | ✅ | Nutzt Dynatrace OneAgent für OTel-Integration und erweiterte Überwachung. |
| Splunk | ✅ | ✅ | ✅ | ✅ | Splunk OTel Distro für nahtlose Integration. |
| Honeycomb | ✅ | ✅ | ✅ | ✅ | Hochdetaillierte Trace-Analyse, Logs/Metriken benötigen zusätzliche Tools. |
Fazit
OpenTelemetry integriert sich hervorragend in unsere Microservice-Systemlandschaft.
Bereits die Standard-Implementierung ermöglicht uns eine sehr umfassende Observability. Die Dokumentation ist sehr gut und eine Erweiterung bzw. Schaffung von eigenen Instrumentierungen ist relativ einfach möglich. Die Technik hilft uns ungemein bei der Analyse von Problemen und der Performance in unseren verteilten Systemen.
Gleichzeitig ersetzt das Tooling nicht das Verständnis hinsichtlich der Implikationen verteilter Systeme in unseren Teams. Eben diese Befähigung unserer Teams stellt die wesentliche Herausforderung dar, der wir fortlaufend mit einem Coaching durch unsere Lead Developer und entsprechende Schulungen begegnen.
Beispiel für eine OpenTelemetry-Instrumentierung
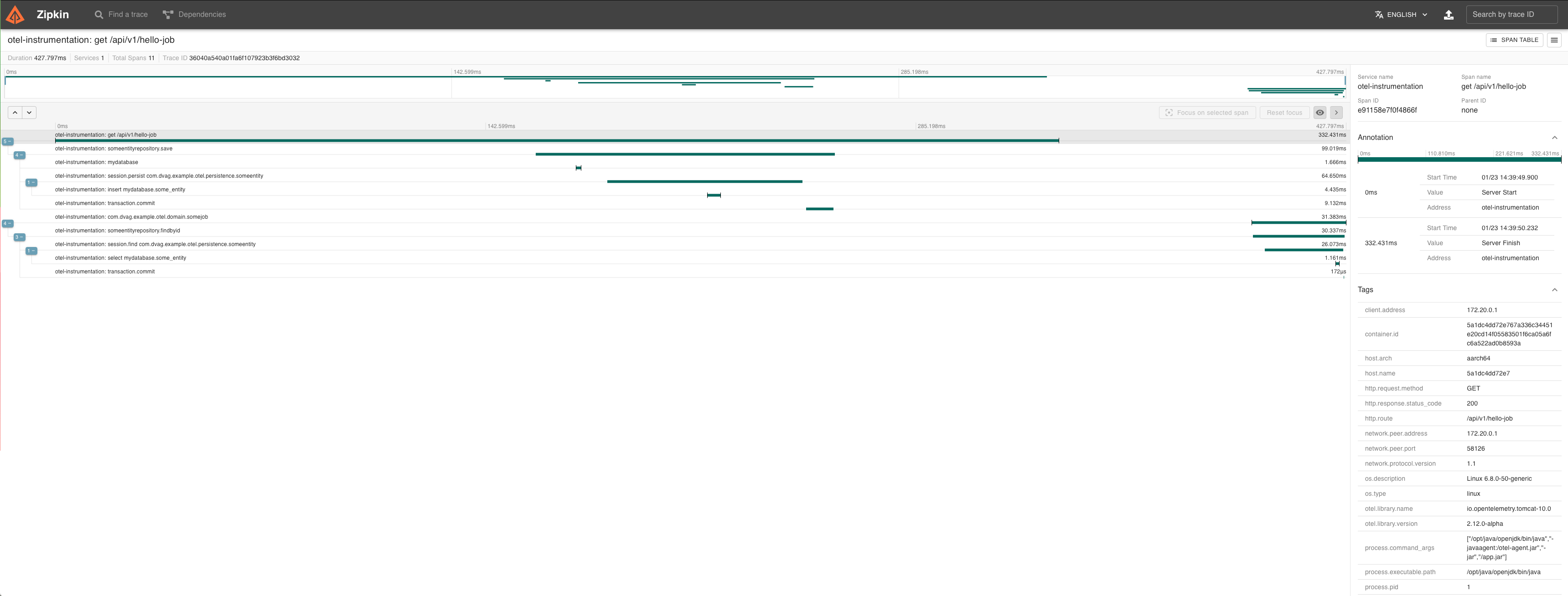
Wir haben ein kleines Beispielprojekt auf Basis von Spring Boot erstellt. Dieses stellen wir Euch als ZIP-Archiv hier zum Download zur Verfügung.
Das Projekt bietet ein minimales Spring Boot-Backend mit einer einfachen HTTP-Schnittstelle,
um die benutzerdefinierte Instrumentierung mit OpenTelemetry zu demonstrieren.
Wir verwenden in unserem Beispiel die nachfolgenden Technologien:
Spring Bootfür das BackendHibernate/JPAfür den DatenbankzugriffQuartzfür die Job-PlanungOpenTelemetryfür TracingZipkinzur einfachen Visualisierung der TracesDockerfür die ContainerisierungPostgreSQLfür die Datenbank
Überblick
Die Demo zeigt, wie eine benutzerdefinierte OpenTelemetry-Instrumentierung implementiert werden kann.
Die Instrumentierung wird in Quartz integriert, um eingehende HTTP-Requests mit geplanten Jobs zu verbinden.
Dieses Beispiel löst ein klassisches Problem: Wie kann eine asynchrone Operation (z. B. ein geplanter Job)
mit einem eingehenden HTTP-Request verknüpft werden?
Überblick über die Instrumentierungsklassen
QuartzTelemetryInstrumentation- Instrumentierung fürQuartz-Jobs, die über einenJobListenervonQuartzaufgerufen wirdQuartzJobFacade- Fassade zum Planen vonQuartz-Jobs, die mit einemSpanausOpenTelemetryverknüpft sindQuartzInstrumentationJobListener-JobListener-Implementierung, umSpansfürQuartz-Jobs zu starten und zu beenden
Demo-Endpunkt
Der Demo-HTTP-Endpunkt /api/v1/hello-job löst einen geplanten Job aus,
der mit dem eingehenden HTTP-Request verknüpft ist und zusätzlich SQL-Operationen ausführt,
um den resultierenden Trace interessanter zu gestalten.
Start des Projekts
Benötigt werden aktuelle Versionen von Docker und Docker Compose.
Sobald Docker läuft, kann das Setup mit folgendem Befehl gestartet werden:
docker compose up --build
Anschließend kann folgendermaßen Last auf dem Service generiert werdne:
curl http://localhost:8080/api/v1/hello-job
Abschließend kann die Zipkin UI geöffnet werden, um die Traces zu visualisieren. Hier kann mittels Klick auf “RUN QUERY” Einblick in die Traces genommen werdne. Anschließend sollten die Traces mit dem Namen otel-instrumentation: get /api/v1/hello-job sichtbar werden. Mit einem weiteren Klick auf den “SHOW”-Button können Details zu den Traces angezeigt werden.