Neue Anwendungen entwickeln wir konsequent als Microservices mit Microfrontends und betreiben diese Cloud Native. Wie wir das machen, haben wir in unseren vergangenen Blogposts berichtet. Neben dieser “neuen Welt” haben wir als Unternehmen mit bald 50-jähriger Historie aber natürlich auch Anwendungen in Betrieb, die noch nicht dieser neuen Architektur folgen.
Die relevanteste Anwendung in diesem Kontext ist unser DVAG Online System. Mit dieser als Fat Client/Server Architektur konzipierten Anwendung haben unsere VermögensberaterInnen heute u.a. Zugriff auf ihre Kundendaten und die Module zur Konfiguration passender Finanzprodukte.
Ausgangslage und Schwächen
Das DVAG Onlinesystem wurde Anfang der 2000er Jahre neu entwickelt und 2004 in den produktiven Betrieb überführt. Seither ist das System “historisch gewachsen” und verfügt über eine große Anzahl von im Laufe der Zeit ergänzten Funktionalitäten, Schnittstellen und von Partnern integrierten Dritt-Lösungen.
Die Prozesse rund um die Themen Release-Management, Build und Deployment wurden ihrer Zeit entsprechend entwickelt und umgesetzt. Besonders im direkten Vergleich mit unseren GitHub-basierten CI/CD-Verfahren für unsere Microservices fielen uns eine Reihe von Schwächen auf:
Erstens haben viele der für das DVAG Online System im Build- und Deployment-Prozess genutzten Technologien das Ende ihres Lebenszyklus erreicht. An die Stelle von bspw. Jenkins, Eclipse RCP und Ant sind in den vergangenen Jahren neue Tools getreten, die einfacher handhabbar sind sowie die Aufgaben schneller und flexibler durchführen können.
Zweitens ist das Build- und Deploymentverfahren des DVAG Online Systems statisch mit Blick auf die durchzuführenden Tätigkeiten. Die Gesamtanwendung besteht aus mehreren hunderten Einzelmodulen, deren Source Codes in eigenständigen Git-Repositories verwaltet werden. Bei Releases beinhalten oft nur einzelne dieser Module tatsächlich Änderungen. Dennoch berücksichtigt der Build- und Deployment-Prozess alle Inhalte in vollem Umfang. Dies führt zu langen Laufzeiten, die während der Release-Aktivitäten zu entsprechenden Wartezeiten für die Beteiligten führen.
Drittens beruhen die Prozesse auf der Annahme, dass bei Releases neuer Versionen des DVAG Online Systems eine geplante Downtime stattfindet. Während dieser arbeiten KollegInnen aus der IT daran, alle notwendigen Aktivitäten durchzuführen, um ein neues Release nach Produktion zu bringen, zu testen und freizugeben. Der Anteil manueller Tätigkeiten ist entsprechend hoch. In Kombination mit der Vielzahl der integrierten Komponenten ist im Laufe der Zeit eine Komplexität entstanden, die tiefes Expertenwissen für die Durchführung von Builds und Deployments erfordert.
In Summe haben wir es daher mit einem gewachsenen, komplexen und von manuellen Schritten geprägten Prozess zu tun.
Zielsetzung
Wir haben uns daher zum Ziel gesetzt, den Build- und Deployment-Prozess des DVAG Online Systems grundlegend zu modernisieren. Hierbei haben wir uns von folgenden Zielen leiten lassen:
- Reduktion der organisatorischen Komplexität: Vereinfachung und hohe Automatisierung der Release-Durchführung. Damit wollen wir einerseits Zeit im Prozess einsparen und andererseits allgemeine manuelle Fehler vermeiden.
- Reduktion der technologischen Komplexität: Einsatz marktführender State-of-the-Art Technologien entsprechend der internen Standards; wo möglich stark angelehnt an die GitHub-basierten CI/CD-Verfahren unserer Microservices zur Erhöhung der Effizienz und Wartbarkeit. Damit einhergehende Reduktion der Technologie-Vielfalt im Prozess auf das notwendige Minimum, womit auch die Verständlichkeit gesteigert wird.
- Kurze Durchlaufzeiten: Minimierung von Downtimes, Erhöhung der Reaktionsfähigkeit im Fehlerfall (MTTR) sowie Entlastung der am Release Beteiligten von Wartezeiten.
- Standardisierung und Automatisierung der Kommunikation: Teams werden automatisiert mit den für sie relevanten Informationen aus dem Build- und Deployment-Prozess versorgt und können im Fehlerfall schneller und effizienter reagieren.
Architektur & Lösung
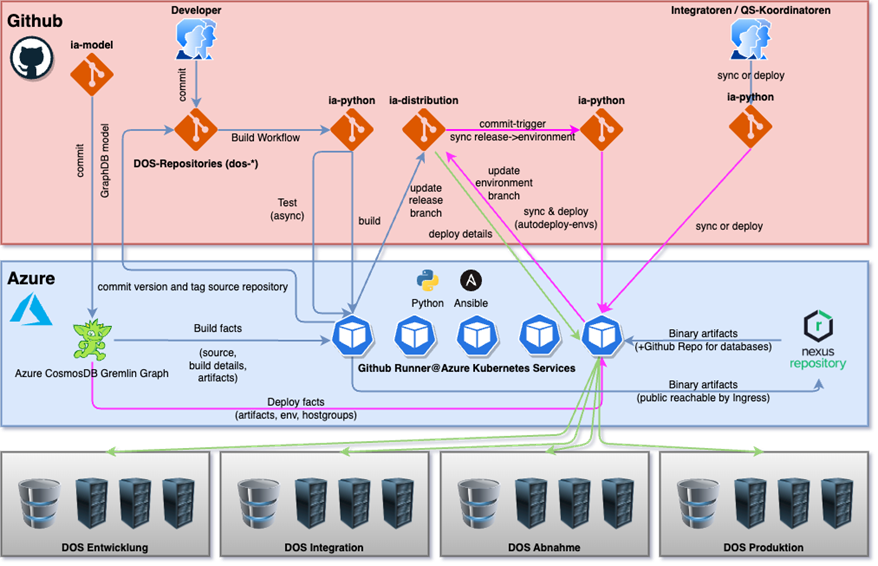
Die Voraussetzung für die Umsetzung war die Migration sämtlicher Repositories von BitBucket nach GitHub. Diese Gelegenheit haben wir genutzt, um Bereinigungen und Modernisierungen in den einzelnen Repositories durchzuführen – bspw. die Migration von Secrets in Azure Key Vaults, um ein einheitliches, effektiv wartbares und modernes Secret Management umzusetzen.
Zunächst haben wir nach Abschluss der GitHub-Migration unsere Builds und Deployments weiterhin teil-automatisiert mittels Jenkins durchgeführt, wobei sich die Jenkins-Jobs die notwendigen Sourcen nicht mehr aus BitBucket, sondern aus den jeweiligen GitHub-Repositories gezogen haben.
Zur Umsetzung der Ziellösung haben wir dann entsprechend unserer oben beschriebenen Zielsetzung folgende Komponenten eingesetzt:
- GitHub Actions: Gemäß der Umsetzung unserer CI/CD für neue Microservices nutzen wir GitHub Workflows, um Softwareartefakte zu compilieren, zu testen und zu deployen.
- GitHub Actions Runner Controller: Wir verwenden die Runner, um die einzelnen Actions durchzuführen – bspw. einen Compile oder ein Deployment in unsere hybride On-Prem-/Cloud-Infrastruktur.
- Azure Kubernetes Cluster mit Anbindung an unser On-Prem-Rechenzentrum: Hier laufen die GitHub Actions Runner. Die Anbindung an unsere On-Prem-Infrastruktur ist notwendig, da das DVAG Online System teilweise in der Azure Cloud und teilweise in unserer On-Prem-Welt betrieben wird.
- Python: Eigenes Scripting haben wir mittels Python umgesetzt. Dadurch ist die gesamte Lösung in einer einheitlichen Programmiersprache mit hoher Marktdurchdringung realisiert.
- Ansible: Das vollautomatische Deployment erfolgt mit Ansible. Ansible ist der weltweite Quasi-Standard für Infrastruktur- und Deployment-Automatisierung. Dadurch müssen wir uns bspw. über Parallelität und Inventories für verschiedene Umgebungen keine Gedanken machen. Da Ansible ebenfalls auf Python basiert, haben wir teilweise eigene Ansible-Module entwickelt.
- Nexus@AKS: Die compilierten Artefakte werden versioniert im Nexus Artifact Repository abgelegt, um sie von dort aus schnell in die jeweiligen Umgebungen deployen zu können.
Fakten und Konfiguration
Die zentralen Fakten und Konfigurationen des Automatisierungsvorgangs speichern wir in einem GitHub-Repository “ia-model”. Hierzu zählen bspw. Informationen über die GitHub-Repositories, die Builds, die Artefakte, die Hostgroups und die Kommunikationswege für Erfolgs- und Fehlermeldungen.
Jeder Commit in dieses Repo führt zu einer automatischen Aufbereitung und Bereitstellung der Daten in einer Azure Cosmos Gremlin GraphDB. Diese ist die Datenquelle für die Durchführung der Automatisierung und steuert mit ihren Daten den gesamten Ablauf. Die Graphen-Datenbank ermöglicht es uns, die relevanten Informationen für den Build-, Sync- und Deployment-Prozess abzurufen und effizient zu verarbeiten.
Releases und Umgebungen
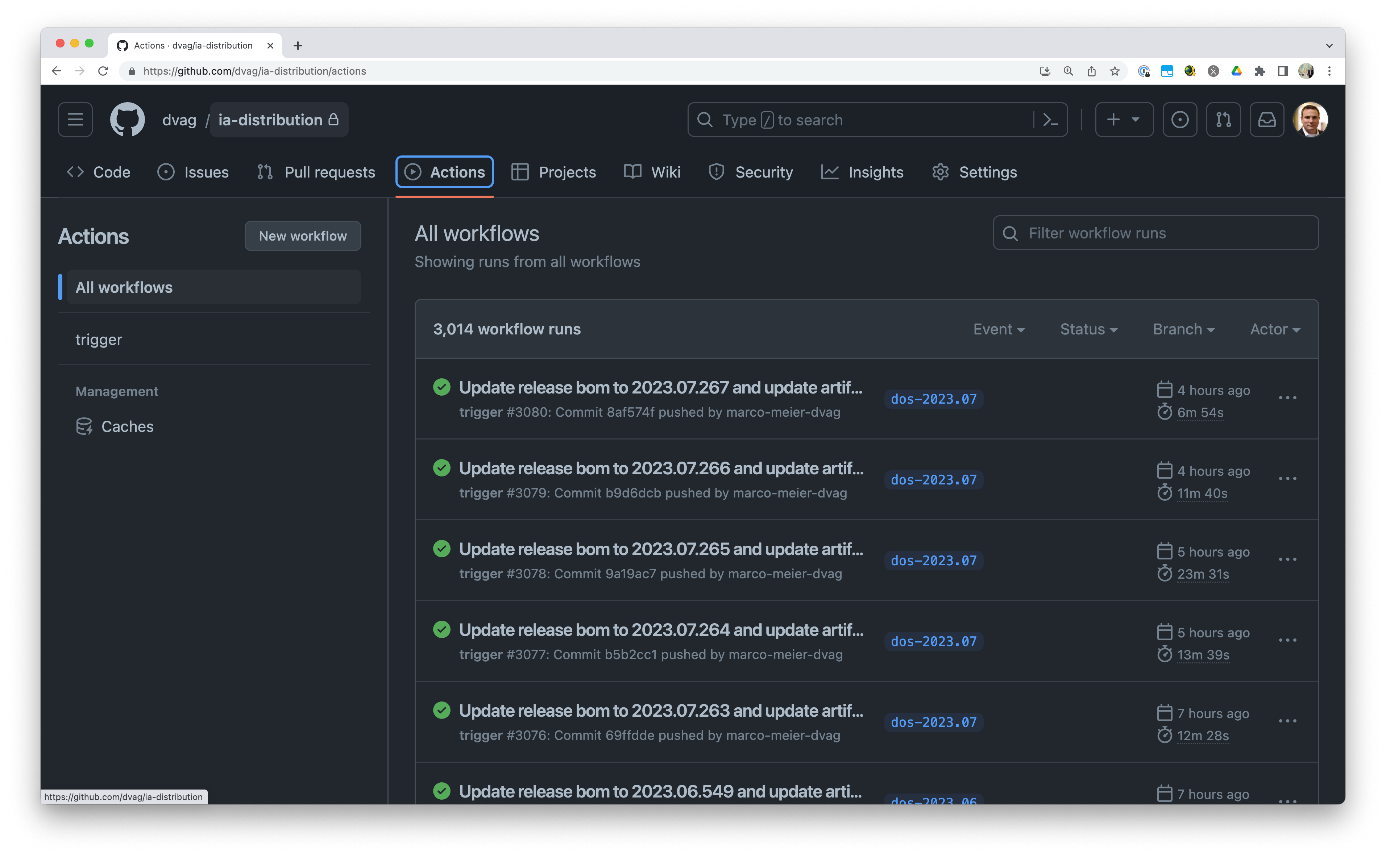
Im GitHub-Repository “ia-distribution” gibt es einen Branch für jedes Release und einen Branch für jede Umgebung. Ein Release enthält dabei die Artefakte und Versionen dieses Releases sowie eine Bill of Material (BOM) für Maven (im Abschnitt “Build” gibt es hierzu weitere Details).
Eine Umgebung enthält Release-Trains mit den Artefakten dieses Trains, dem Deploy-Status des jeweiligen Artefakts und das Ansible Inventory mit allen Hostgroups und Hosts.
Build
Jeder Code-Commit in einem GitHub-Repository führt automatisch zu einem Build der Artefakte. Im Anschluss an den Build werden die neuen Versionen in das Code-Repository commitet und das Release im GitHub Repository “ia-distribution” aktualisiert. Basierend auf Repository und Branch des Commits entscheidet der Automat mit den Informationen aus der GraphDB, welcher Release-Branch im “ia-distribution” zu verwenden ist.
Im Falle eines Commits in einem Datenbank-Repository wird kein Package im Nexus abgelegt, sondern lediglich ein Tag im Github Repository erzeugt. Ein Datenbank-Package ist entweder ein Full Package oder ein inkrementelles Package. Das heißt, eine neue Version ersetzt die bereits im Release vorhandene Version oder wird als zusätzliches Package ergänzt. Der Datenbankentwickler hat vielfältige Steuerungsmöglichkeiten über eine deployment.yaml in seinem Repository. Er kann damit z. B. temporäre Packages ersetzen, Abhängigkeiten zu anderen Paketen definieren und Umgebungen für ein Deployment explizit ein- oder ausschließen.
In einer Bill of Material (BOM) halten wir fest, aus welchen Komponenten in welchen Versionsständen ein Softwareartefakt besteht. Es gibt innerhalb des DVAG Online Systems eigenentwickelte Komponenten sowie Komponenten, die uns bspw. von unseren Produktpartnern zugeliefert werden. Jeder Build führt daher zu einem vollautomatischen Update der neu gebauten Versionen in der Release-BOM. Jedes Release hat seine eigene Release-BOM und dadurch sein eigenes Set an Versionen. Jede Komponente bekommt im Build die neueste Version der Release-BOM zur Verfügung gestellt. Auf diese Weise ist es möglich, jedem Build vollautomatisch und konsistent die jeweils aktuellen Versionen zur Verfügung zu stellen.
Sync
Vor jedem Deployment wird ein Sync durchgeführt. Hierbei wird das Quell-Release mit dem Release-Train auf der jeweiligen Umgebung abgeglichen und ein Deployment-Plan erstellt. Dies beinhaltet unter anderem einen Deployment-Plan für Datenbankpakete. Dabei werden die Informationen aus den Commits der Datenbankpakete berücksichtigt. Dies umfasst beispielsweise Abhängigkeiten der Pakete untereinander, Pakete, die ersetzt werden müssen, Umgebungen, auf die ein Paket nicht deployed werden soll, die Definition einer ggf. notwendige Downtime oder ein notwendiger Restart.
Basierend auf diesen Informationen wird ein gerichteter azyklischer Graph (directed acyclic graph, DAG) erzeugt und ein Datenbank Deployment Plan festgelegt. Sämtliche Pakete, die parallel deployed werden können, werden im Sinne der Optimierung der Laufzeiten auch parallel deployed. Abhängige Pakete werden entsprechend danach deployed. Der Deployment-Plan enthält hierfür Parallelitätsgruppen. Innerhalb einer Gruppe werden alle Pakete parallel und die Gruppen selbst werden sequenziell ausgeführt.
Der Sync ergänzt, basierend auf GraphDB-Informationen, welche Artefakte auf welche Hostgroups ausgerollt werden sollen. Ein Artefakt kann dabei auf eine einzelne Hostgroup oder auch beliebig viele Hostgroups verteilt werden. Eine Hostgroup beinhaltet dann immer mehrere Hosts zum Zwecke der Lastverteilung und der Stabilität.
Build und Deployment sind völlig unabhängig voneinander. Dadurch ist jederzeit ein Wechsel eines Releases zwischen den Umgebungen und die Wiederholung von Deployments möglich, ohne erneut einen Build durchführen zu müssen. Dies spart uns in Summe eine Menge Zeit ein.
Deployment
Das eigentliche Deployment wird von Ansible parallel und basierend auf dem Ansible Inventory der Umgebung ausgeführt. Dabei werden – wieder im Sinne der Laufzeitoptimierung – nur Komponenten berücksichtigt, die sich tatsächlich geändert haben.
Ein solches Deployment erfolgt automatisch in hierfür gemäß den Informationen aus der Graphen-Datenbank vorgesehene Umgebungen. Deployments in eine andere Umgebung können manuell durch das Starten des entsprechenden Ansible-Prozesses oder mit Hilfe eines GitHub-Workflows ausgelöst werden. Dabei muss das gewünschte Quell-Release und die Zielumgebung ausgewählt werden.
Kommunikation
In unserer umfassenden CI/CD-Lösung legen wir großen Wert auf eine effiziente Kommunikation zu den Teams, die für die einzelnen Softwareartefakte zuständig sind. Diese stellt sicher, dass alle relevanten Stakeholder zeitnah über den Build- oder Deployment-Status informiert werden. Die Kommunikationsziele werden dabei einfach in der GraphDB für jeden Build, jedes Artefakt und jede Umgebung hinterlegt. Dabei können sowohl Mailadressen als auch Teams-Channel hinterlegt werden. Dadurch ist es beispielsweise möglich, dass Entwicklungsteams eigene Teams-Channel anlegen, um dort nur Informationen zu Aktivitäten ihrer eigenen Repositories zu erhalten.
Darüber hinaus ist es möglich, eine Unterscheidung zwischen Informationen, Erfolgs- und Fehlermeldungen vorzunehmen. Es gibt beispielsweise für jede Umgebung einen Channel mit allen Meldungen und einen Channel, in dem sich nur Fehlermeldungen befinden. Es ist für viele Entwicklungs-Teams somit ausreichend, die Teams-Benachrichtigungen für den Fehler-Channel zu abonnieren und diesen zu überwachen, um auf kritische Informationen sofort reagieren zu können.
In den Messages sind alle für die Adressarten benötigten Informationen enthalten. Dies umfasst beispielsweise Informationen zu den gebauten Artefakten, erfolgreich oder fehlerhaft deployte Artefakte, Logfiles für Datenbank-Package-Deployments und Versionsnummern. Außerdem sind immer die Links zu alle relevanten Repositories und Workflow-Runs enthalten, um schnell weitere Informationen abrufen zu können.
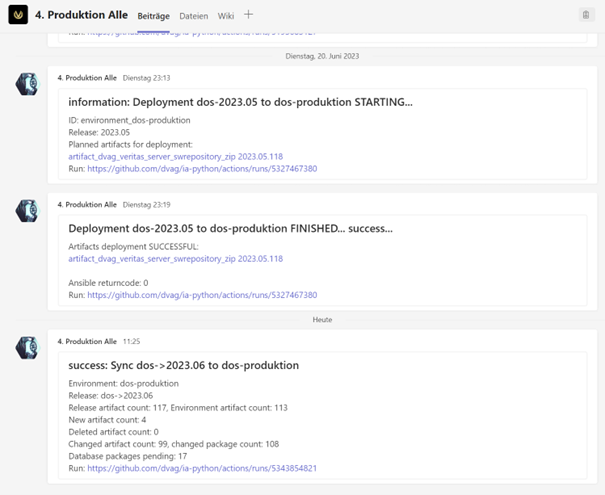
Dies alles ermöglicht eine effektive und transparente Zusammenarbeit zwischen den Teammitgliedern, da sie alle Aktivitäten des Automaten und alle relevanten Informationen sofort erhalten. Durch die Integration in bestehende Kommunikationstools wie Microsoft Teams erleichtern wir die Zusammenarbeit und fördern den Wissensaustausch zwischen den Teams.
GitHub Actions Runner
Bei jedem anstehenden Build, Sync oder Deployment wird mittels des Actions Runner Controllers (ARC) automatisch ein im Azure Kubernetes Service (AKS) gehosteter GitHub Actions Runner gestartet. Diese AKS Runner nutzen mittels Express Route eine Direktverbindung von Microsoft Azure zu unseren On-Prem-Rechenzentren. Deployments sind dadurch in unsere hybride Landschaft möglich, d.h. sowohl in unsere On-Prem-Systeme als auch auf unsere Cloud-Umgebungen.
Die Nutzung des Automaten ist nicht nur innerhalb von GitHub möglich. Es kann jederzeit ein AKS-Container gestartet und der Automaten-Prozess dann darin ausgeführt werden. Das erhöht die Resilienz des gesamten Systems und führt dazu, dass es keine zwingende Abhängigkeit zur CI/CD-Lösung gibt.
Fazit
Mit der Modernisierung und weitreichenden Automatisierung der Build- und Deploymentprozesse rund um unsere relevantesten Legacy-Systeme konnten wir die Laufzeiten erheblich verringern und unseren Entwicklern und Testern ein deutlich effizienteres Arbeiten ermöglichen.
Dies wird an einem Vergleich deutlich sichtbar: Dauerte ein Hotfix-Deployment im bisherigen System ca. 5 Stunden, ist der gleiche Prozess im neuen Verfahren nach ca. 12 Minuten abgeschlossen. Dadurch können wir Fehler schneller in Produktion beheben, Downtimes vermeiden und die Service Level gegenüber unseren NutzerInnen merklich verbessern.
Im selben Zuge haben wir die Anzahl der im Prozess eingesetzten Technologien auf ein Minimum reduziert. Bei den zum Einsatz gebrachten Technologien handelt es sich ausschließlich um state-of-the-art Cloud-Technologien, die in unseren neuen CI/CD Prozessen zum Einsatz kommen. Die Verwendung dieser neuen Standards auf unseren Legacy-Systemen erhöht sowohl die Wartbarkeit als auch die Verständlichkeit für alle beteiligten KollegInnen.
Die durch die Modernisierung des Build- und Deploymentprozesses erreichte Steigerung der Effizienz und Resilienz rund um die entsprechenden Legacy-Systeme erlaubt unseren Teams eine stärkere Fokussierung auf die zukunftsgerichteten Themen. Außerdem ermöglicht diese Vorgehensweise es immer weiteren Teams, sich mit unseren modernen Technologie-Stacks und –Standards vertraut zu machen und sich auf die aktuelle Zielarchitektur auszurichten.
Diese inzwischen erfolgreich implementierte Modernisierungsinitiative hat uns gezeigt, dass wir durch den Einsatz unserer moderner Technologie-Standards und Methoden auch unsere Legacy-Prozesse und -Systeme noch einmal deutlich optimieren und unseren Kunden einen besseren Service auf den bekannten Feldern bieten können.